
這位開發者製作了一個圖文並茂的互動網站來幫助你了解神經網路( neural network ) 是如何建立起來的,理解原理後比較不會迷失在那些已經包裝好的程式庫
以下是為這個圖文並茂做的筆記,你也可以直接進入網站,按下 Start 就可以開始了
這個網站上方有一些瀏覽按鈕,可以用這些瀏覽按鈕跳到不同的章節,如果你要直接玩已經建立好的神經網路可以直接點選 「SANDBOX」
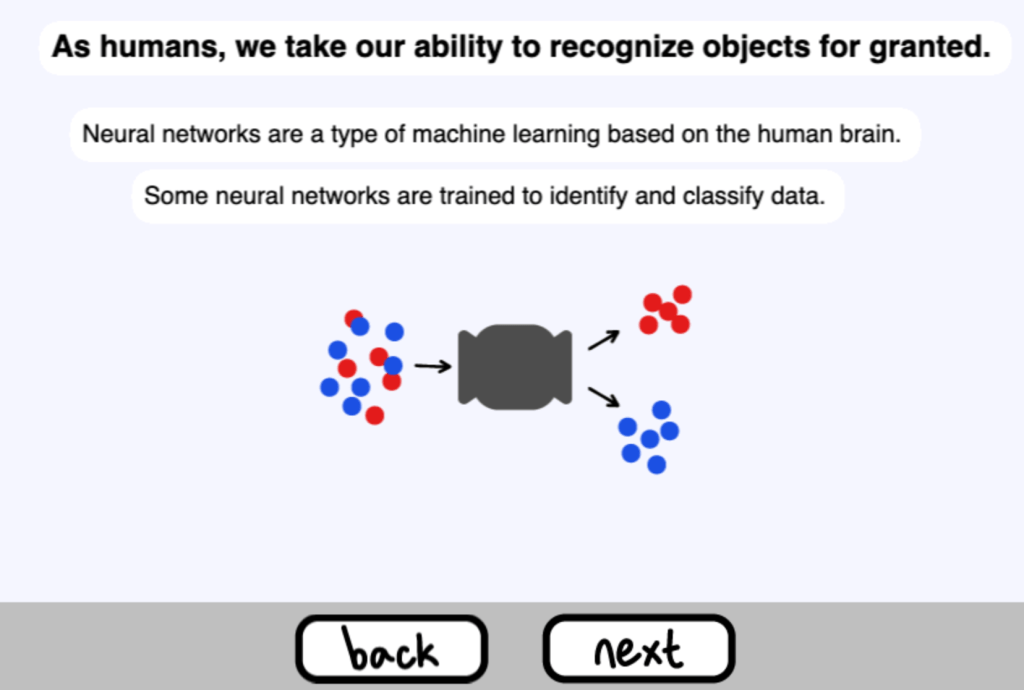
作為人類,我們認為我們識別物體的能力是理所當然的。
神經網路是一種基於人腦的機器學習。
一些神經網路被訓練來識別和分類資料
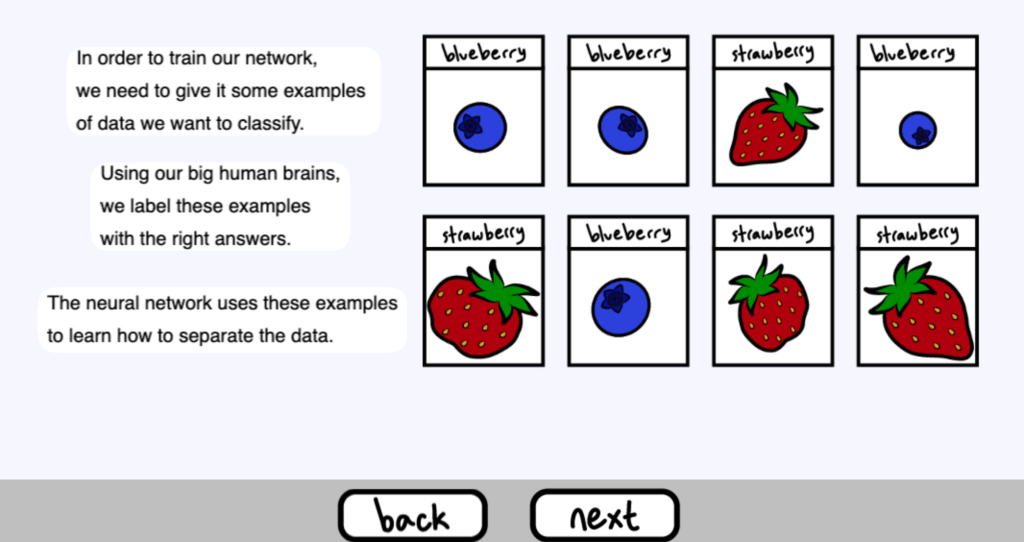
為了訓練我們的網路,我們需要給它一些我們想要分類的資料的範例
用我們人類的大腦袋,我們給這些範例貼上正確的答案。
神經網路使用這些範例來學習如何識別資料。
如果你曾經為了進入一個網站而不得不解決這樣一個謎題
你可能是在幫助標註資料以訓練神經網路

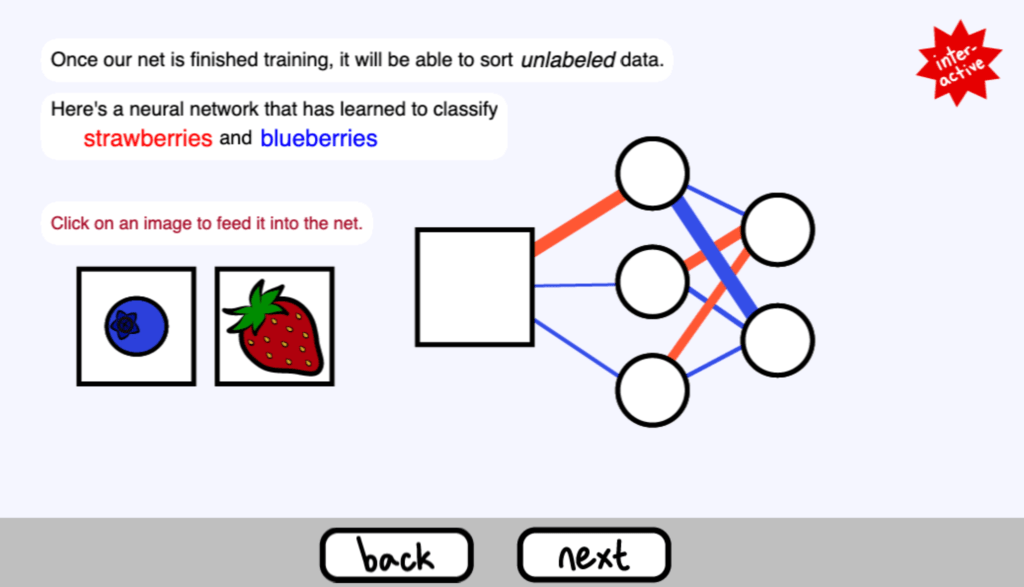
一旦我們的網路完成了訓練,它將能夠對未標記的資料進行分類。
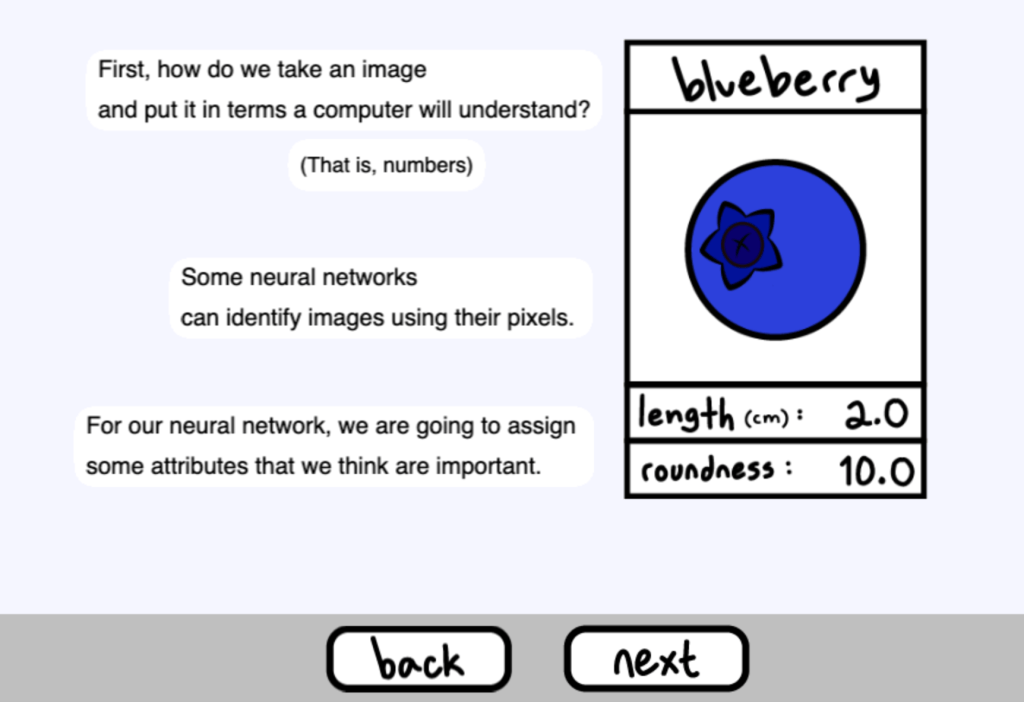
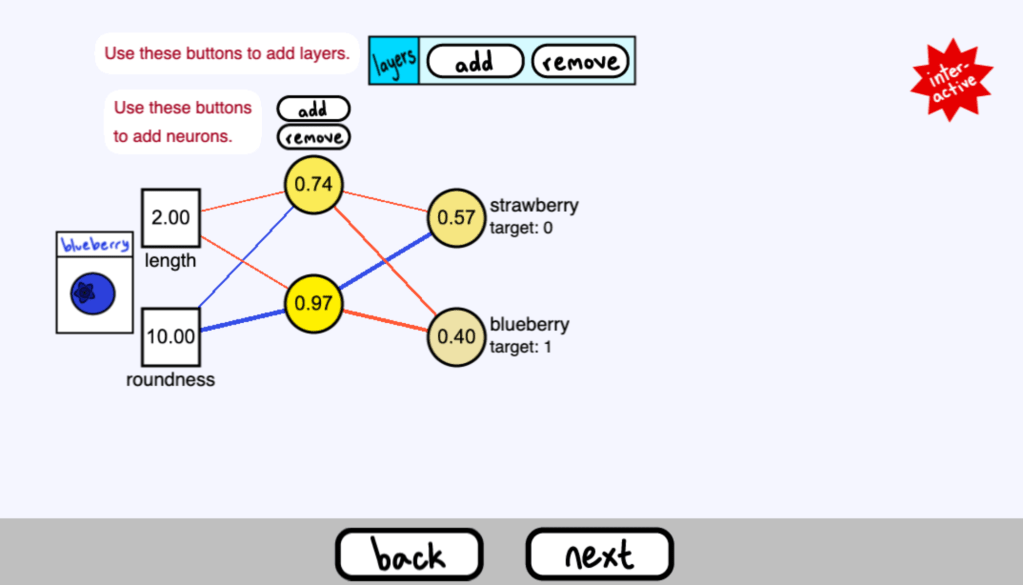
下面是一個已經學會對草莓和藍莓進行分類的神經網路
首先,我們如何將一幅影象以電腦能夠理解的方式表達出來?( 也就是數字 )
一些神經網路可以使用其畫素( pixel )來識別影像。
對於我們的神經網路,我們將分配一些我們認為重要的屬性。
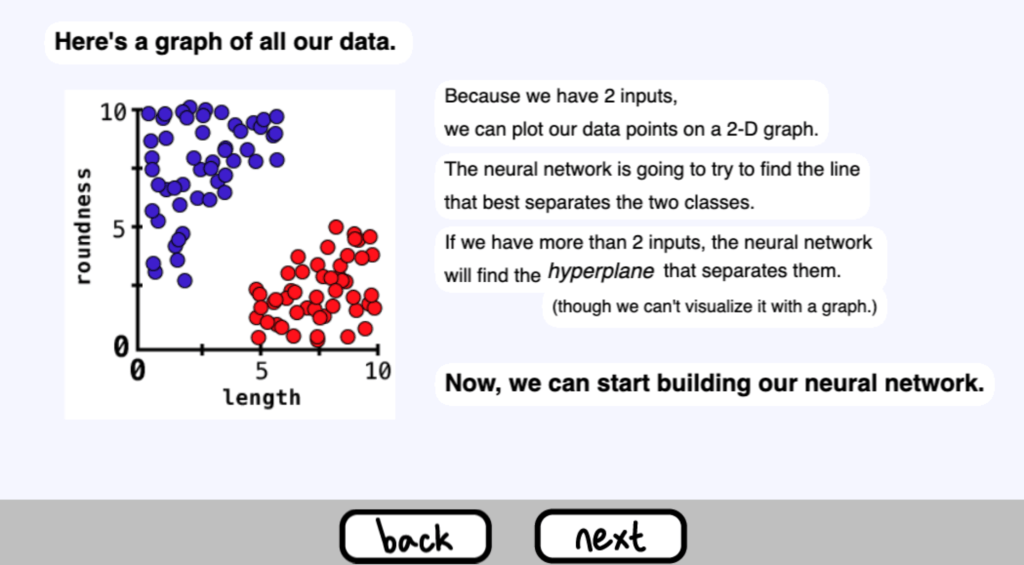
因為我們有2個輸入,所以我們可以將資料點繪製在一個二維圖上。( x 軸是長度,y 軸是真圓度 )
神經網路將試圖找到最能區分兩類的線。
如果我們有2個以上的輸入,神經網路將找到分離它們的超平面。(但我們不能用圖形來顯示它。)
現在,我們可以開始建立我們的神經網路了。
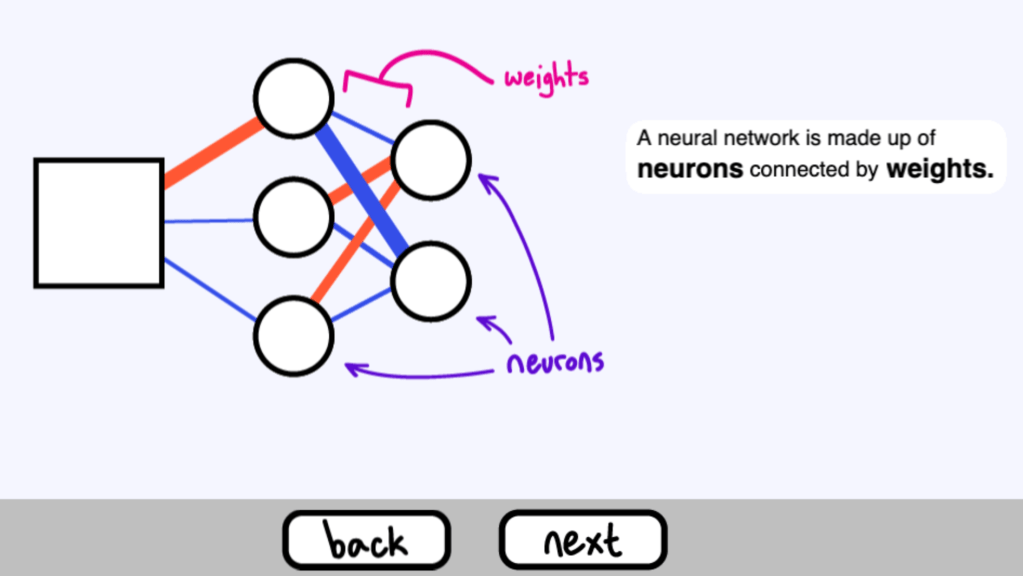
一個神經網路是由神經元( neurons ) 組成的,透過權重( weights ) 來連結
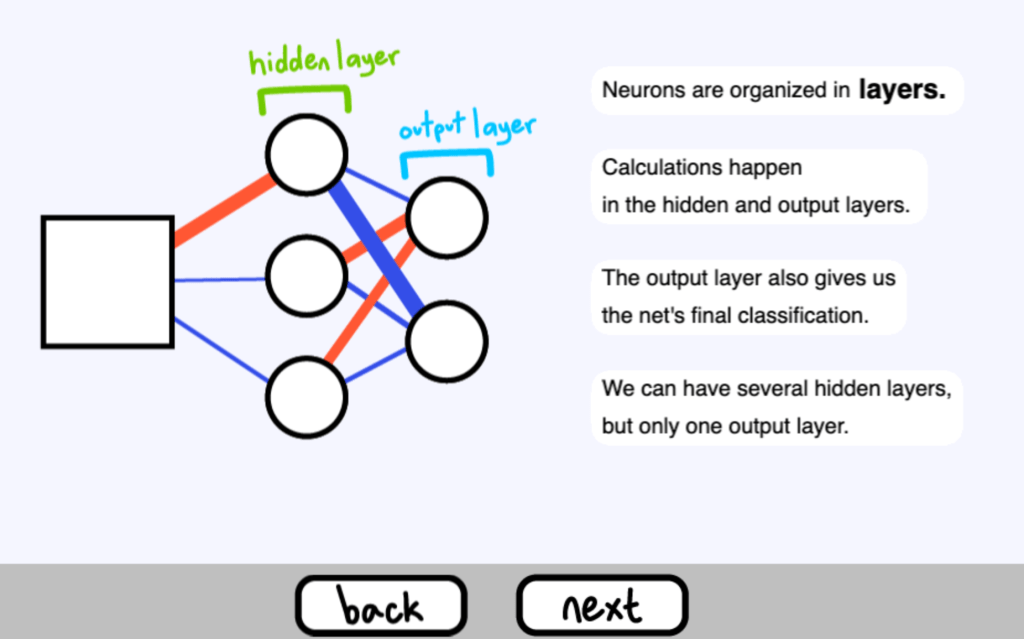
神經元是分層組織的。
運算發生在隱藏層( hidden layer ) 和輸出層( output layer ) 。
輸出層也為我們提供了網路的最終分類。
我們可以有幾個隱藏層,但只有一個輸出層。
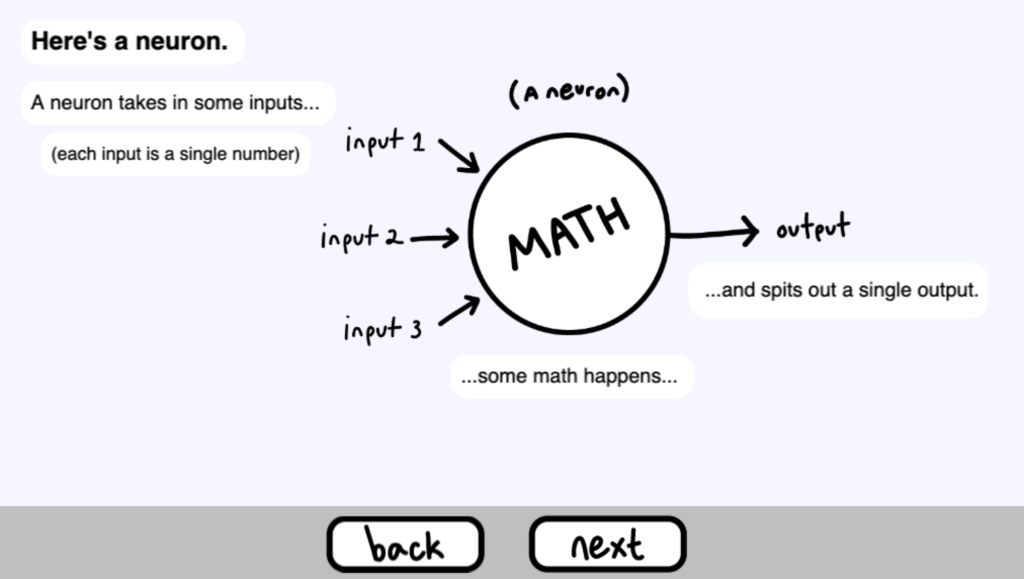
這裡有一個神經元( neuron )。
一個神經元接受一些輸入……(每個輸入是一個單一的數字 )
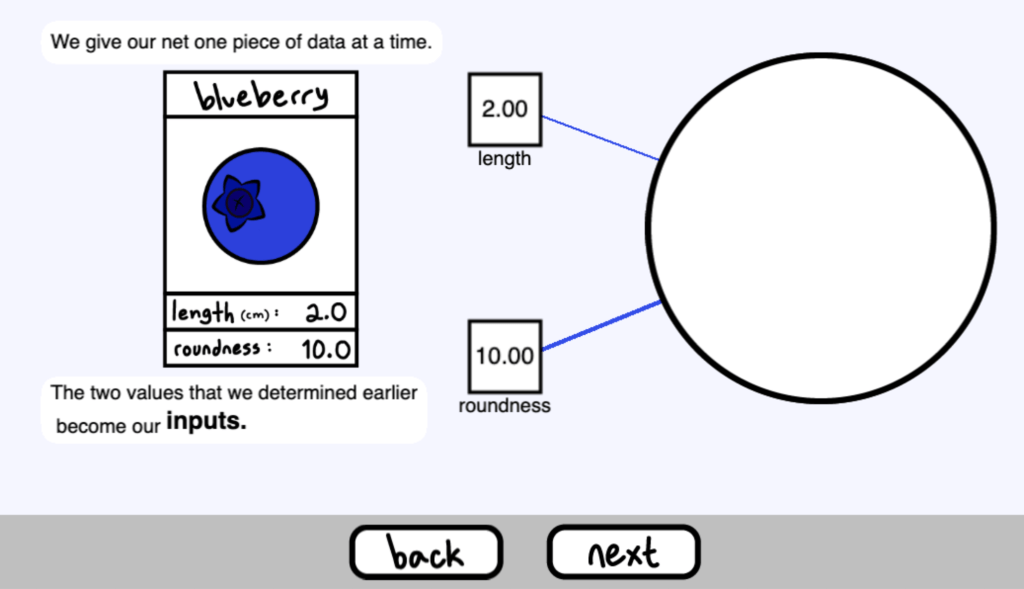
我們每次都給我們的網路提供一個數據
我們之前確定的兩個值成為我們的輸入值( inputs )
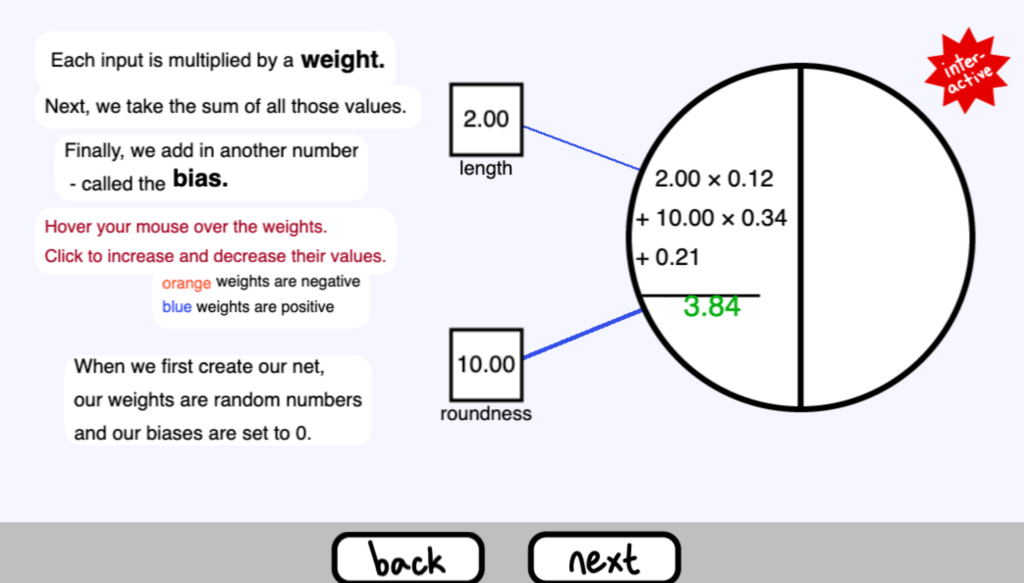
每個輸入都要乘以一個權重。
接下來,我們取所有這些值的總和。
最後,我們加入另一個數字–稱為偏差值( bias )
將你的滑鼠懸停在權重上。點選來增加和減少它們的值。( 當你瀏覽到這個頁面,這個頁面是互動的,你可以將滑鼠移到輸入的地方來修改權重 )
當我們第一次建立我們的網路時,我們的權重是隨機數,我們的偏差被設定為0。
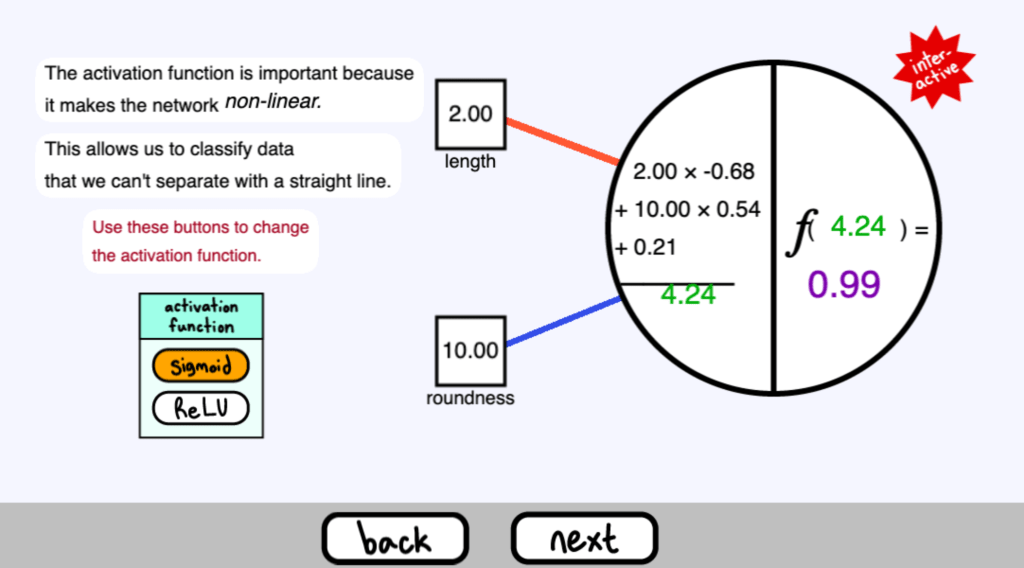
接下來,我們將最後一個值插入一個啟用函式( activation function ) 中
現在,我們正在使用 sigmoid 函式
這將我們的輸出壓在 0 和 1 之間。

另一個啟用函式( activation function ) 被稱為整流線性單元( Rectified Linear Unit ) ,簡稱ReLU

啟用函式很重要,因為它使網路為非線性( non-linear ) 。
這使我們能夠對那些我們無法用直線分離的資料進行分類
使用這些按鈕來改變啟用函式。( 這個頁面是可互動的 )
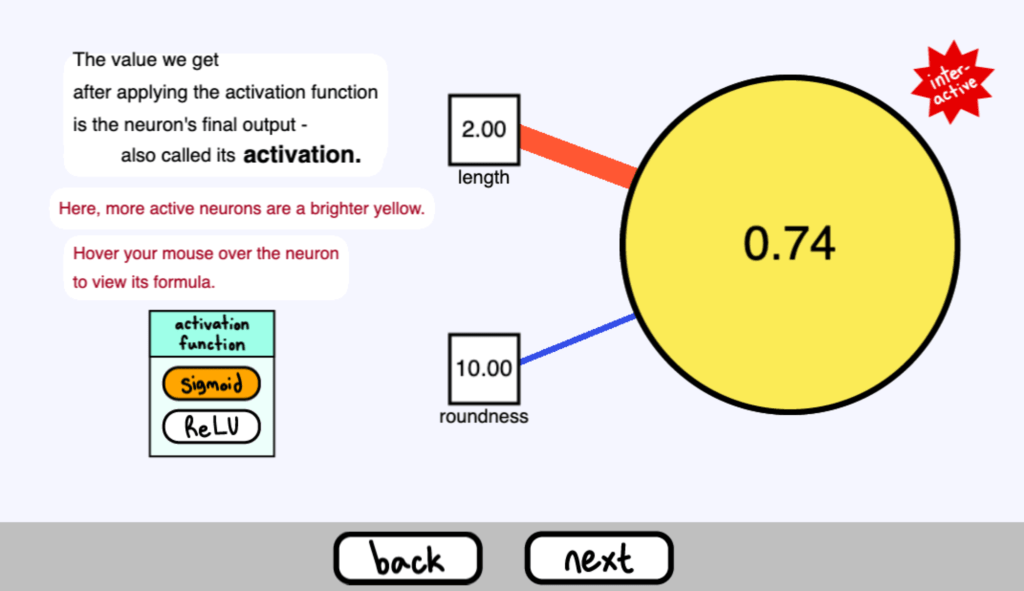
我們在應用啟用函式後得到的值是神經元的最終輸出–也稱為其啟用 ( activation )。
在這裡,更活躍的神經元是一個更明亮的黃色
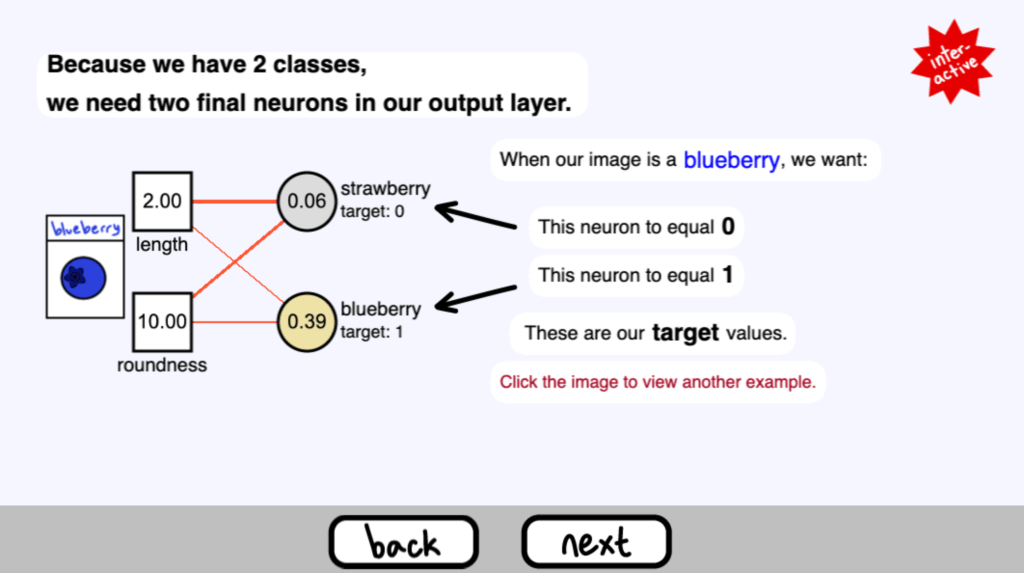
因為我們有兩個類別,所以我們的輸出層需要兩個最終神經元。
當我們的影像是一個藍莓時,我們希望。
這個草莓的神經元的輸出等於0
這個藍莓的神經元輸出等於1
這些是我們的目標值
( 在這個頁面你可以點選影像來看另一個影像的輸出結果 )
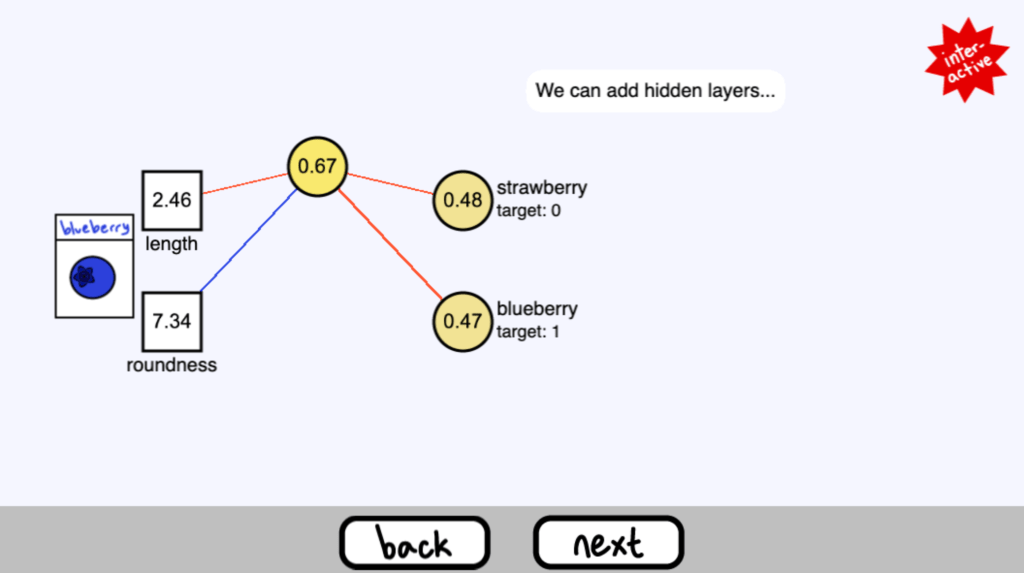
我們可以加入隱藏層
我們可以新增隱藏層…
…並為每個隱藏層新增神經元。
注意一個層的輸出是如何成為下一個層的輸入的
這個從輸入到最終輸出的過程被稱為正向傳播( forward propogation )。
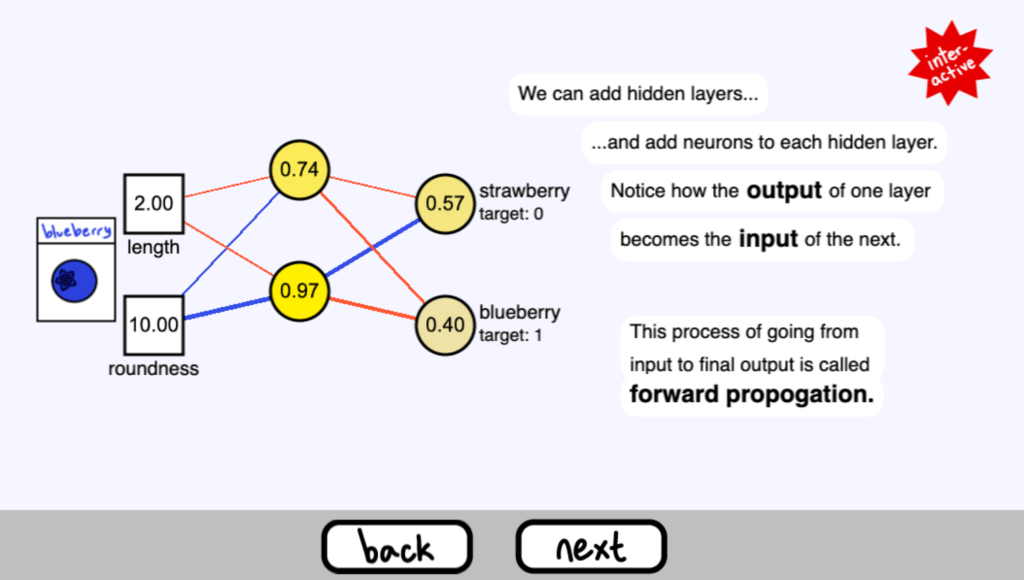
使用畫面上的按鈕來加入層
現在我們已經建立了我們的網路,我們可以開始訓練它。
這是神經網路學習如何分離資料的階段。
為了學習,該網路使用了一種叫做反向傳播 ( backpropogation ) 的演算法。

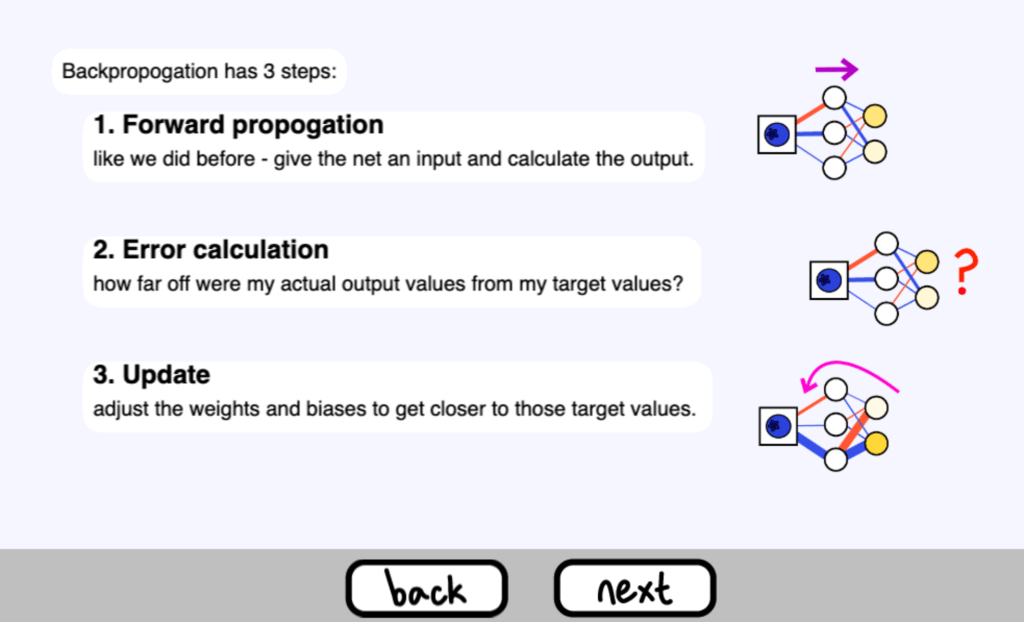
反向傳播有 3 個步驟
1 正向傳播
就像我們之前做的那樣–給網路一個輸入並計算出輸出
2 錯誤計算
我的實際輸出值與目標值相差多遠?
3 更新
調整權重和偏差,使之更接近這些目標值
我們想知道我們的網路的輸出與我們的目標值有多大的偏差。
為了做到這一點,我們使用一個成本函式 ( cost function ) -> n = 資料點的數量,x = 每一個神經元的輸出
輸出神經元的啟用( activation ) 取決於網路的當前權重( weight )和偏差( bias ) 。
因此,我們可以把我們的成本函式看作是網路的權重和偏差的一個函式

一個資料點的成本 ( cost ) 計算範例
注意改變權重如何改變輸出,從而改變成本

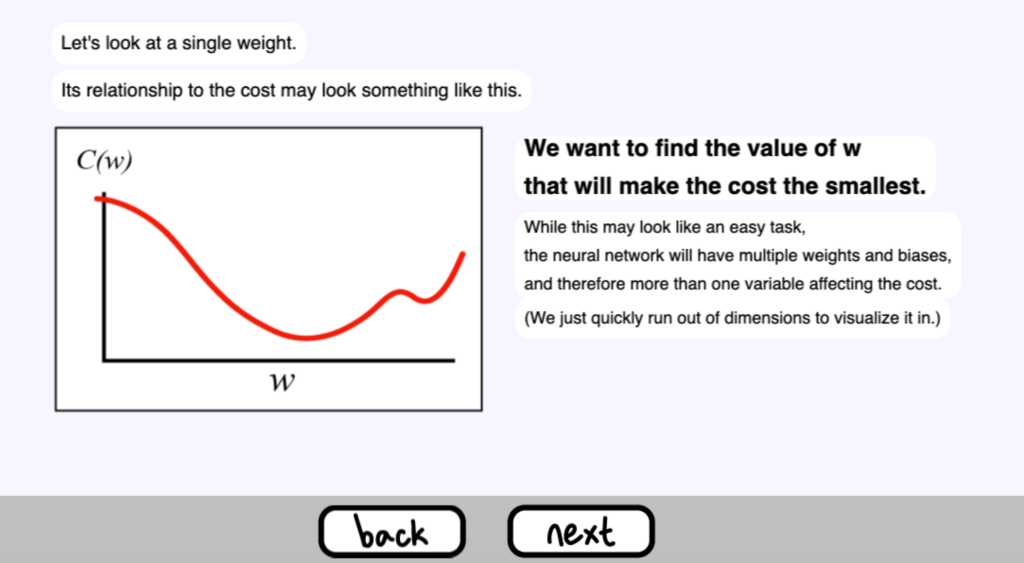
讓我們來看看一個單一的權重
它與成本的關係可能看起來像這樣 ( 圖示 )
我們想找到能使成本最小的 w 值。
雖然這看起來是個簡單的任務。
神經網路將有多個權重和偏差,因此影響成本的變數不止一個。
(我們很快就沒有維度可以將其視覺化了)
神經網路調整其權重和偏差,以使用一種稱為梯度下降( gradient descent )的演算法使成本( cost )最小化。
首先,我們找到當前的權重和成本。
接下來,我們找到這一點上的斜率( slope ),或圖形的梯度( gradient ) 。這個寫成

以下簡稱梯度

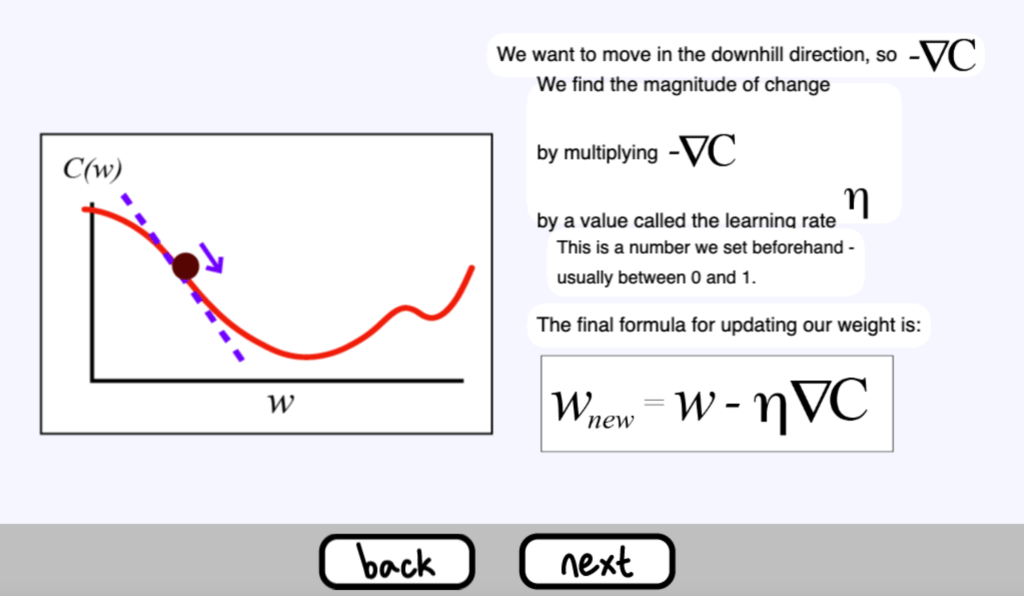
我們想向下坡方向移動,所以是負的梯度
透過將負的梯度乘以一個稱為學習率( learning rate ) 的數值來實現。
這是一個我們事先設定的數字–通常在0和1之間。
更新我們權重的最終公式是
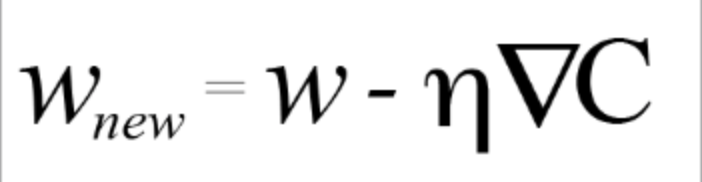
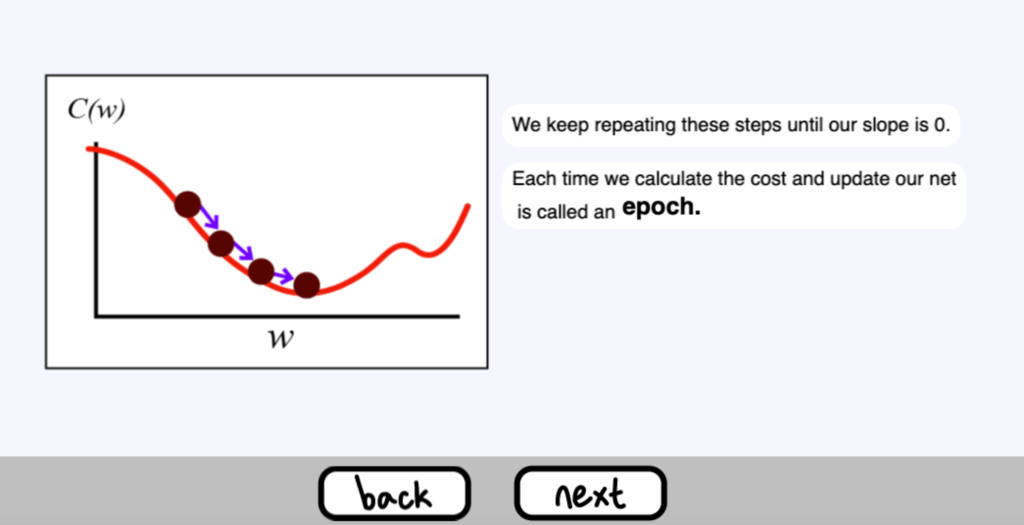
我們不斷地重複這些步驟,直到我們的梯度( slop ) 為0。
每次我們計算成本和更新我們的網路時,都被稱為 epoch
學習率的大小很重要
太小的話,需要很長的時間才能達到最小值。
太大的話,我們最終可能會跳過最小值。

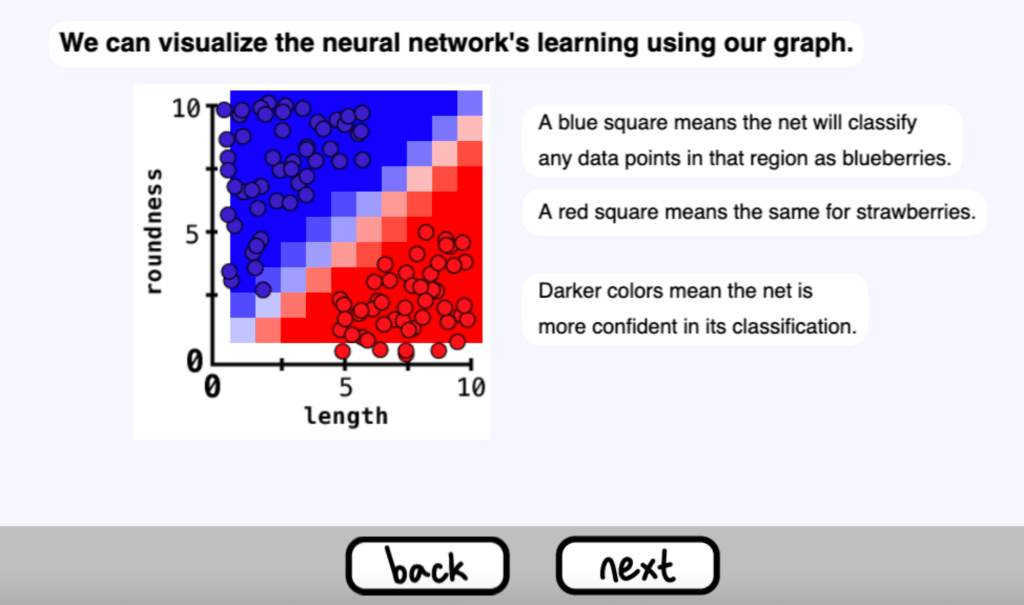
我們可以使用我們的圖表來視覺化神經網路的學習情況
一個藍色的方塊意味著網路將把該區域的任何資料點歸類為藍莓。
紅色方塊意味著對草莓也是如此
較深的顏色意味著網路對其分類更有信心
想看看梯度下降背後的微積分嗎?( 這部分就請大家自己看了 )
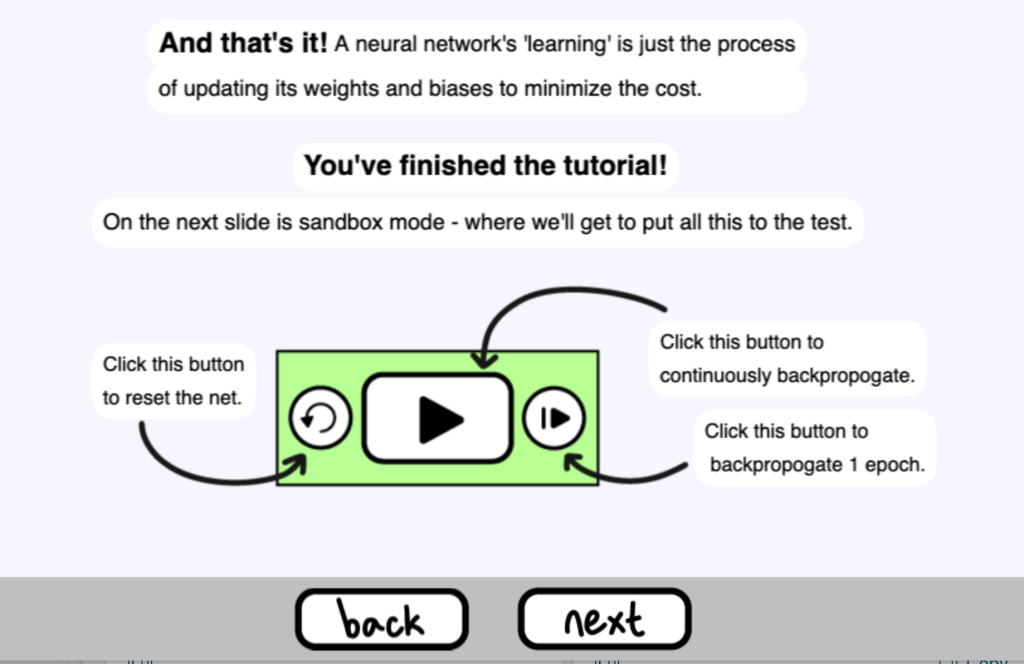
就是這樣!神經網路的 “學習 “只是更新其權重和偏差以使成本最小化的過程。接下來你可以到 Sandbox 模式觀看整個訓練的過程,可以自動執行不斷地反向傳播,或是每次只執行一次 epoch
這個教學指南的建議者
網址
不受 FB 演算法影響,歡迎透過 e-mail 訂閱網站更新
支持 Soft & Share
❤️您應該有留意到,我們的網頁並不會出現干擾人的跳出煩人的廣告或是在內容中嵌入廣告,因為我們發現這樣對閱讀網頁的內容體驗真的是不好!
如果您覺得我們提供的內容服務還不錯,歡迎透過對以下產品/服務的購買投資來支持本站的營運走得更遠
如果暫時還不需要以下的付費服務,幫我們把這個網站分享給有需要的朋友,您的小小舉動會對 Soft & Share 有莫大的幫助!感謝您的支持!
🎈如果您點選優惠連結後,還是沒有看到優惠價格,請將瀏覽器的 cookie 清除 ( 清除 udemy 網站的就可以了 ),然後重新點選優惠連結並登入 Udemy 就可以了
- ❤️歡迎透過我們的 A-Z 關鍵字索引 或 Udemy 策展找到您想要的課程
- ❤️更多付費服務(電子書/其他線上課程平台/軟體服務 )……
你必須登入才能發表留言。