
來自Soft & Share 資料分析與機械學習版主ricky的分享, 對於ricky的分享有任何問題, 歡迎加入slack聊天室討論
前言
對於多數人來說,我們處理的資料通常不會做前提假設就直接放入機器學習模型,而這也使得我們在訓練模型的時候會很可惜地浪費許多迭代時間,甚至無意造成過度擬合。今天和大家分享的事情是,如果你事先能先掌握你的輸入資料的一些機率統計性質,這樣的話可以幫助你來做類神經網路初始化權重並達到更快更好的迭代收斂效果。
初始化權重要旨:保持各層輸出值變異數相等
讓我們先簡單思考,如果我建立一個類神經網路模型,在第一筆輸入資料搭配初始化權重之下,第一層隱藏層輸出到第二層做輸入值分別為 [1,2,3,400,500,6] 你會有什麼感覺?肯定 400 與 500 這兩個第二層輸入值之前一定有部分第一層的神經元乘上了一個很大的權重,才會得到那麼大的值。
如果後續權重修正的過程不如人意,前面提到的這兩個超大權重沒有被大幅修正的話,很有可能讓你的整個類神經網路模型產生了【依賴路徑】無形中你的類神經網路模型也開始變得會和你一樣有「先入為主的刻板印象」了。
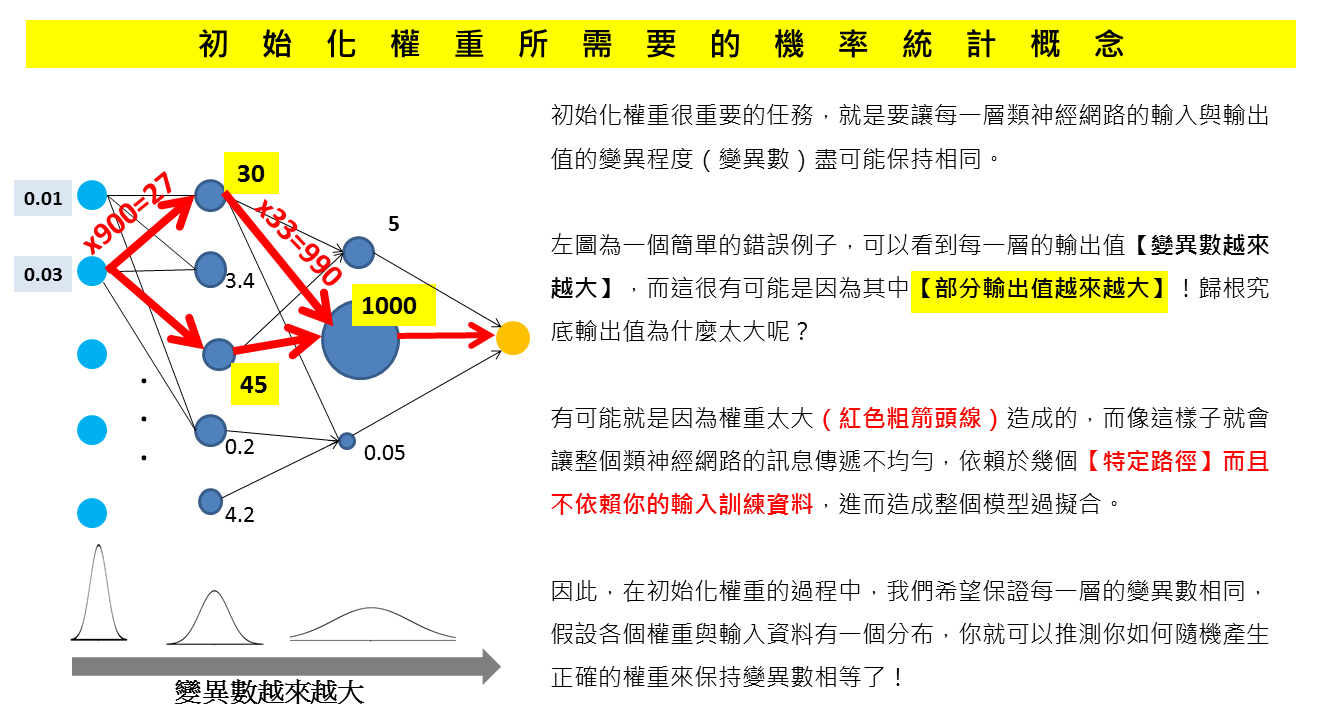
為了避免這個結果,我們可以在事先先假設每一層的輸出值的變異數要相等,利用各階期望值公式與 i.i.d.性質(獨立等同分佈)回推前一層的權重與輸入值應該有怎麼樣大小的變異數,倘若你的輸入資料有某些特別的屬性,例如可能假設服從卜瓦松分佈(等待時間)或服從指數分佈(壽命),而且你沒有事先把它變到 [-1,1] 或 [0,1] ,那保持每一層的輸入輸出的變異數就變成很重要的功課了!
如果你想要立即採用本文的方法改進模型,可以進一步閱讀 Understanding the difficulty of training deep feedforward neural networks 其中有提到初始權重可以透過一個根據各層神經元個數的均勻分布來產生,進而達成輸入輸出值各層之間始終保持變異數相等的機率統計性質,進而讓模型中的訊息傳遞過程更平均分散。
About Me
RICKY,目前任職於瑞典摩爾資產管理,擔任小小 Quant (P-measure), 主要擅長混合新聞短訊與時間序列資料的複合式機器學習模型開發, 近一年來主要深耕於流形學習(manifold learning)盼能在中文世界遇到熟的知音
對於這篇文章有任何問題, 歡迎到https://github.com/softnshare/datanmachlearn/issues/3 留言
關於Soft & Share
Soft & Share目前有經營 FB團購社群 並會透過slack召開網路讀書會, 有興趣歡迎來加入, Soft & Share也是廣受開發者喜愛的開發工具JetBrains合作夥伴, 歡迎透過Facebook搜尋 “JetBrains Taiwan” 即可找到JetBrains開發工具的社群, 歡迎加入社群討論.
最近招募中的網路讀書會
Soft & Share 的讀書會願景- 我們希望每本書會是一個連結, 最後這個連結會形成一個網路, 這個網路甚至會誕生新的創意, 這個新的創意會對社會有幫助, 讓人的生活變得更美好.
目前招募中的網路讀書會請參考這個頁面
喜歡我們的分享嗎? 記得使用以下社群分享按鈕分享給您的社群朋友吧!
發表迴響