
原文 : Top Machine Learning Interview Questions for 2018 (Part-1) 註: 原文有 18 個問題,我們將分三單元來翻譯
接續 2018 年機器學習面試最常問的問題 ( 1 – 1 )
Q7. 你能比較一下決策樹( Decision Trees )和線性迴歸( linear regression )嗎? 決策樹能用於非線性分類( non-linear classification )嗎?
決策樹同時用於無監督的和監督式學習的。 同時,它們也被用於分類( classification )和監督式學習問題的迴歸。 在決策樹中,我們通過分割節點( splitting the node )來形成樹。 最初,所有樣本實例( instances )根據一個邊界被分成兩部分,以便兩邊的樣本實例( instances )是非常接近同一邊的其他樣本實例( instances )的邊界。 左側的樣本實例( instances )應該與左側的其他樣本實例( instances )非常相似,右側的樣本實例( instances )也是如此。
下圖顯示了最大深度 2 和最大深度 3 的決策樹; 你可以看到,隨著決策樹的最大深度的增加,你將獲得更好的可用資料覆蓋率。
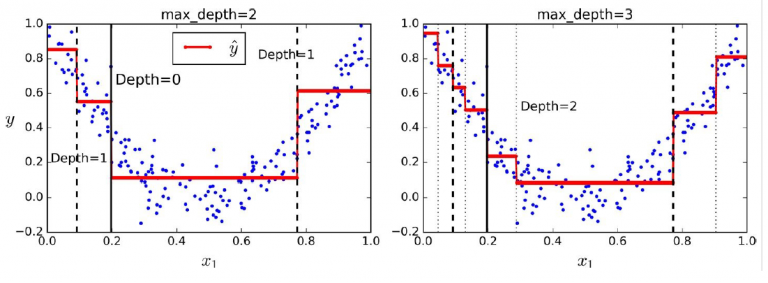
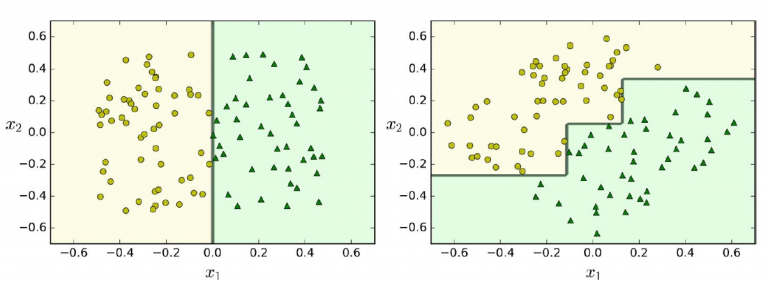
另一個值得強調的決策樹方面是決策樹的穩定性。 決策樹對資料集的旋轉非常敏感。 下圖顯示了資料旋轉時決策樹的不穩定性。
更多詳情請訪問機器學習專業化
Q8. 解釋過度彌合( overfitting )和彌合不足( underfitting )? 是什麼導致了過度彌合?
比如說,有兩個孩子傑克和吉爾參加數學考試。 傑克只學了一些附加知識,吉爾記住了數學書上的問題和答案。 現在,誰能通過這次考試? 答案是兩者都不是。 用機器學習的行話來說,傑克彌合不足( underfitting ),吉爾過度彌合( overfitting )。
過度彌合( overfitting )是演算法無法推廣到不在訓練集( training set )中的新案例,同時演算法對訓練集資料非常有效,就像吉爾可以回答書中的問題,但除此之外什麼都沒有。 另一方面,彌合不足( underfitting )指的是當它不能抓到資料(訓練資料和測試資料)背後的趨勢模型。 補救措施,一般來說,是選擇一個更好(更復雜)的機器學習演算法。
因此,彌合不足( underfitting )模型是那些在訓練和測試資料方面表現不佳的模型。 在開發機器學習演算法時密切觀察對過度彌合是非常重要的。 這是因為,憑直覺,如果模型與訓練集非常吻合,開發人員傾向於認為演算法工作得很好,有時沒有考慮到過度彌合的問題。 當模型相對於訓練資料的數量和噪音過於複雜時,就會發生過度彌合。 這也意味著該演算法對測試資料的處理效果不好,可能是因為測試資料與訓練資料的分佈不同。
以下是一些避免過度彌合的方法:
- 簡化模型: 正規化,以超參數來控制
- 收集更多的訓練資料
- 減少訓練資料中的噪音
以下是一些避免彌合不足的方法:
- 選擇一個更強大的模式
- 為學習演算法提供更好的特徵
- 減少模型上的約束(減少正規化超參數)
Q9. 什麼是交叉驗證技術?
讓我們來了解一下什麼是驗證集( validation set ),然後我們會去交叉驗證。 在建立模型時,需要通過反向傳播( backpropagation )的方法對訓練集進行權重調整。 且這些權重的選擇使得訓練誤差最小。
現在,你需要資料來評估模型和超參數,而這些資料不能與訓練集( training set )資料相同。 因此,訓練集資料的一部分被保留用於驗證,並稱為驗證集。 當測試不同的模型,使用交叉驗證技術保持分開的驗證集,以避免浪費太多資料在模型的驗證上。 在交叉驗證技術上,訓練資料被分成互補的子集,不同的模型使用不同的訓練和驗證集。
最後利用測試資料對最優的模型進行檢驗。
更多詳情請訪問機器學習專業化
Q10. 你如何檢測過度彌合和彌合不足?
這是實戰機器學習中最重要的問題之一。 為了回答這個問題,讓我們來理解偏差( bias )和方差( variance )的概念。
為了判斷演算法是否過度彌合還是彌合不足,你需要找出訓練集誤差( E_train ) 和交叉驗證集誤差( E_cv )。 如果你的 E_train 高,E_cv 也在 E_train 相同的範圍內,即 E_train 和 E_cv 都高。 這是高偏差( bias )和演算法彌合不足的情況。 在另一種情況下,比如說,你的訓練設定錯誤很低,但是你的交叉驗證設定錯誤很高: E_train 低,E_cv 高。 這是高方差( variance )的情況,演算法是過度彌合。
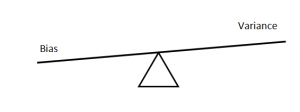
Q11. 什麼是偏差( bias )和方差( variance )之間的權衡?
簡單地說,你可以理解一個非常簡單的演算法(它不抓資料的基本細節) 彌合不足,有很高的偏差( bias )和一個非常複雜的演算法過度彌合且有很高的方差( variance )。 這兩者之間必須有一個平衡。 下圖描述了它們之間的權衡關係。
Q12. 你如何克服上面提到的演算法中的過度彌合?
如上所述,克服過度彌合的方法如下:
- 簡化模型: 正規化,以超參數來控制
- 收集更多的訓練資料
- 降低訓練資料中的噪音
續集 : 2018 年機器學習面試最常問的問題 ( 1 – 3 )
CLOUD x LAB 的實驗室功能介紹
NEW YEAR 20% off
Soft&Share 為 Cloudxlab 聯盟,獲授權翻譯 CloudxLab 上所有資訊
發表迴響