
原文 : Top Machine Learning Interview Questions for 2018 (Part-1) 註: 原文有 18 個問題,我們將分三單元來翻譯
接續
Q13. 有一個同事聲稱他建立的分類器( classifier )已經達到了99.99% 的準確率? 你會相信他嗎? 如果沒有,主要嫌疑點會是什麼? 你會怎麼解決它?
99.99% 是一個非常高的準確率,一般來說,應該被懷疑。 至少要仔細分析資料集和將周圍建模解決方案的任何流程做徹底的檢查。 我的主要懷疑物件是資料集和問題陳述。 例如: 在一組手寫字元中,有從 0 到 9 的數字,如果建立一個模型來檢測一個數字是 5 或不是 5。 如果一個錯誤的模型總是將一個數字識別為 8,那麼它的準確率也會達到 90% ,因為所有數字在資料集中都對到相等的數影像。
在這種情況下,資料集對於檢測 5 或不是 5 的問題沒有良好的分佈。
Q14. 解釋一下 ROC 曲線是如何運作的?
ROC 曲線( ROC Curve )
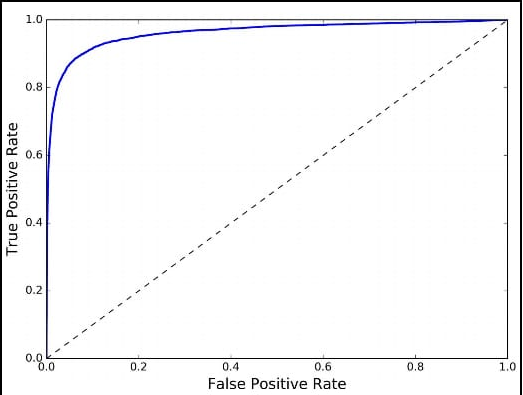
ROC 是 Receiver Operating Characteristic 的縮寫。 ROC 曲線用於衡量不同演算法的效能。 這是在繪製真陽性率( True Positive Rate,TPR )和假陽性率( False Positive Rate,FPR )時對曲線下面積的測量。 面積越大,模型越好。
更多詳情請訪問機器學習專業化
Q15. 解釋整合方法? 基本原則是什麼?
比如你向成千上萬的人提出一個問題,然後彙總答案,很多時候這個答案比專家的答案要好。 整合方法基本上是結合分類、迴歸等不同學習演算法的預測,以達到更高的精度。 這種綜合預測優於最好的個體預測。 這組預報器被稱為合成( ensemble ),這種技術被稱為合成整合學習( ensemble learning )。
Q16. 比如,你有一個以城市 ID 作為特徵的資料集,你會怎麼做?
當你為你的機器學習專案收集資料時,你需要仔細地從收集的資料中選擇特徵( features )。 城市 ID 只是一個序列號,除非另有說明,否則它不代表城市的任何屬性,所以我只是從特徵列表( feature list )中刪除城市 ID。
Q17. 在資料集中,有特徵 hour_of_the_day 從 0 到 23,你覺得 OK 嗎 ?
這個特徵不能使用,因為它是因為一個簡單的原因,每天的小時可能意味著你的問題解決使用機器學習技術的某種約束,但有一個缺陷,若採用這樣的特徵… 考慮 0 和 23,這兩個數字有很大的數值差異,但實際上,它們在當天的實際出現時間上非常接近,因此演算法可能不會產生預期的結果。 有兩種方法可以解決這個問題。 首先是應用週期為 24 小時( 一天有 24 小時 )的正弦函式,這樣可以從不連續的資料中得到連續的資料。
第二種方法是根據你對問題領域的瞭解,將一天的時間分為早上、下午、晚上、夜晚等等,或者分為高峰時段和非高峰時段。
Q18. 如果你有一個較小的資料集,將如何處理?
有多種方法來處理這個問題。 下面是一些技巧。
- 增加資料
- 預先訓練的模型
- 更好的演算法
- 開始生成資料
- 從網路上下載
更多詳情請訪問機器學習專業化
此原文翻譯結束
CLOUD x LAB 的實驗室功能介紹
Soft&Share 為 Cloudxlab 聯盟,獲授權翻譯 CloudxLab 上所有資訊
發表迴響