
在這個以專案學習、長達 2 小時的課程中,你將使用 Python 建構和評估一個簡單的線性迴歸模型。你將使用 scikit-learn 模組來計算線性迴歸,將 pandas 用於資料管理,將 seaborn 用於繪圖。你將使用非常流行的廣告資料集,根據在電視、廣播和報紙等媒體上的廣告支出預測銷售收入。
專案說明 :
本課程在 Coursera 的動手專案平台 Rhyme 上運行。在 Rhyme 上,你可以立即訪問包含專案所需的所有軟體和資料的預配置雲端桌面。一切都已直接在你的網路瀏覽器中設置,因此你可以專注於學習。 對於此專案,你將通過 Jupyter 和 Python 3.7 即時訪問雲端桌面,並預先安裝了所有必需的程式庫( libraries )。

在這指導專案中,你將:
- 向技術和非技術受眾解釋線性迴歸的核心思想
- 使用 scikit-learn 在Python 建構簡單的線性迴歸模型
- 將探索性資料分析(EDA)應用於包含 seaborn和 pandas 的小型資料集
- 使用適當的指標評估簡單的線性迴歸模型
注意:
- 你將能夠訪問雲端桌面 5 次。但是,你將可以根據需要多次訪問說明教學。
- 本課程最適合北美地區的學習者。我們目前正在努力在其他地區提供相同的體驗。
分步進行學習
在與你的工作區一起在分屏播放的視訊中,你的授課老師將帶領你完成每個步驟:
- 介紹與概述
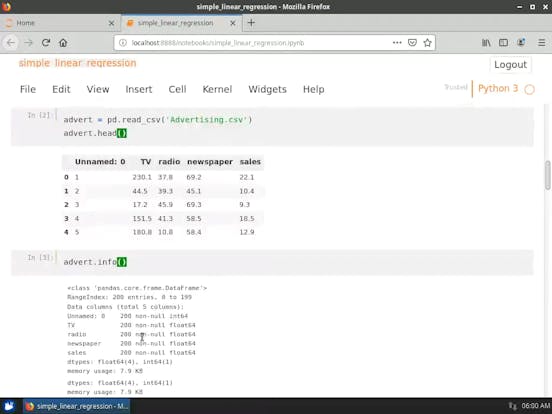
- 載入資料和輸入程式庫( libraries)
- 移除索引欄( index column )
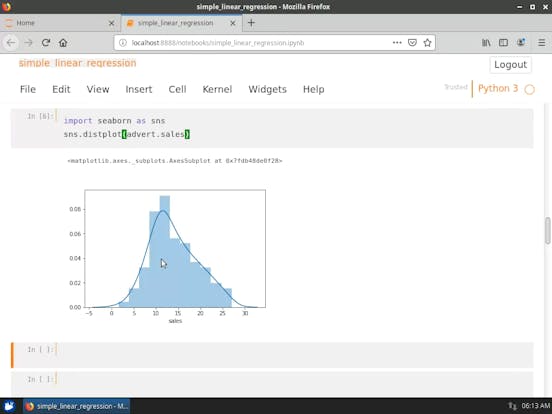
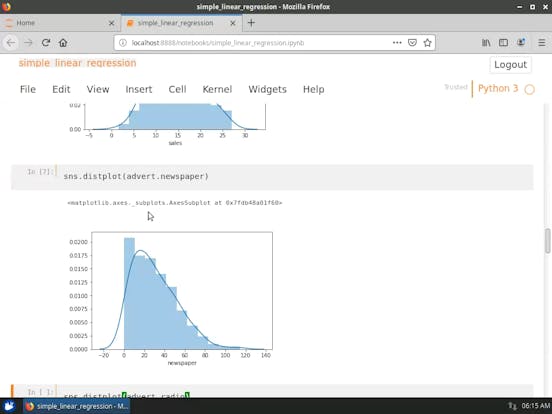
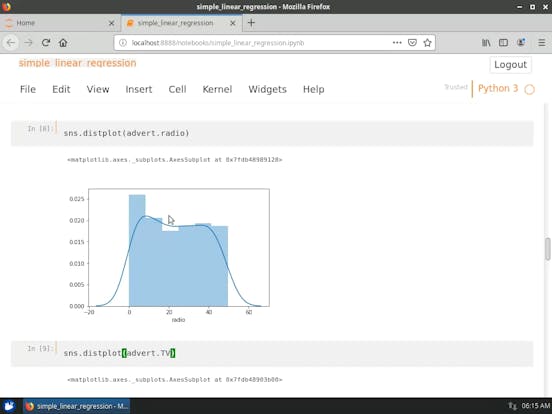
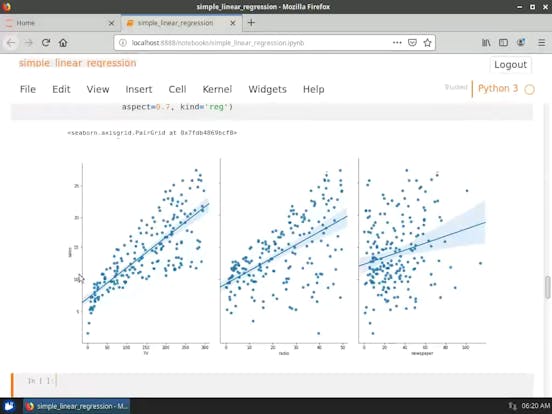
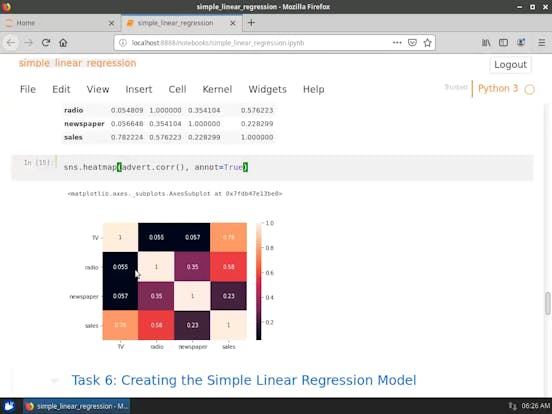
- 探索性資料分析( Exploratory Data Analysis ,EDA)
- 預測( Predictors ) 與回應( Response ) 之間的關係
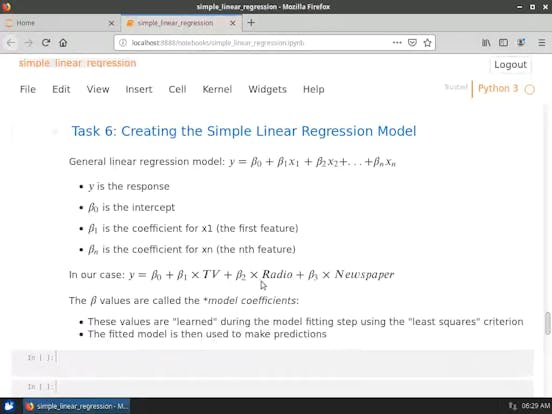
- 創建簡單的線性迴歸模組( Linear Regression Model )
- 評估與模型參數(Model Parameters )
- 採用模組來做預測
- 建模評估指數( Metrics )
你的指導老師
Snehan Kekre 機器學習講師 ( 更多講師主講課程介紹 )
Snehan Kekre 是 Coursera 的機器學習和資料科學講師。
他在位於舊金山的 KGI Minerva Schools 學習計算機科學和人工智慧。他的興趣包括 AI 安全性、EdTech 和教學設計。
他認識到,為了發展 AI 安全的社群,有必要讓學生與工程師對機器學習和 AI 在技術上具備深層的理解。這種熱情驅使他在 Rhyme 上設計基於專案的動手實踐機器學習課程。
追蹤 Soft & Share
✍ 不受社群推薦演算法影響,建議 Telegram/Discord/e-mail


發表迴響